DeepSeek的150人小團(tuán)隊(duì),怎么就讓硅谷顫抖了?
2000活躍值=1RMB
- 類型:注冊任務(wù)
-
任務(wù)總數(shù)
2000
-
參與人數(shù)
0
SemiAnalysis 是一家精品半導(dǎo)體研究和咨詢公司。Dylan Patel是SemiAnalysis首席分析師。這是Dylan Patel新鮮出爐的Deepseek 分析。
筆記俠對本份報(bào)告進(jìn)行了翻譯,第一時(shí)間分享給最近在持續(xù)關(guān)注Deepseek 的俠友們。
這份報(bào)告的核心,是指出DeepSeek憑借“多頭潛在注意力(MLA)”等創(chuàng)新技術(shù),顯著降低推理成本;結(jié)合專家混合模型(MoE)的動態(tài)路由算法和多標(biāo)記預(yù)測技術(shù),實(shí)現(xiàn)算法效率的指數(shù)級提升,推動相同算力下模型性能的跨越式發(fā)展。
同時(shí),在組織架構(gòu)上,DeepSeek通過扁平化架構(gòu)、自建數(shù)據(jù)中心、頂尖人才戰(zhàn)略(百萬美元級薪酬挖角清北精英),形成遠(yuǎn)超谷歌等巨頭的創(chuàng)新速度,是中國AI初創(chuàng)企業(yè)首次在核心算法層面對西方形成實(shí)質(zhì)性挑戰(zhàn)。
一、DeepSeek如風(fēng)暴般席卷全球
DeepSeek 風(fēng)靡全球。在過去的一周里,DeepSeek 是世界上唯一一個(gè)想談?wù)摰脑掝}。就目前而言,DeepSeek 的每日流量現(xiàn)在遠(yuǎn)高于 Claude、Perplexity 甚至 Gemini。
但對于觀察者來說,這并不完全是“新”新聞。DeepSeek已經(jīng)有幾個(gè)月了。這家公司并不是新公司。
DeepSeek非常有才華,美國更廣泛的公眾并不關(guān)心。當(dāng)世界最終關(guān)注時(shí),它在一種不反映現(xiàn)實(shí)的強(qiáng)迫性炒作中得到了關(guān)注。
我們想強(qiáng)調(diào)的是,現(xiàn)在算法的改進(jìn)太快了,這對英偉達(dá)和GPU來說也是不利的。
現(xiàn)在的情況是,DeepSeek非常高效,不需要更多的計(jì)算,而由于模型的改變,所有東西現(xiàn)在都出現(xiàn)了巨大的產(chǎn)能過剩。雖然杰文斯悖論也被過度炒作,但杰文斯更接近現(xiàn)實(shí),模型已經(jīng)誘導(dǎo)了需求,對H100和H200的定價(jià)產(chǎn)生了實(shí)際影響。

二、DeepSeek和High-Flyer(幻方量化基金)
High-Flyer(幻方)是一家中國對沖基金,是使用人工智能進(jìn)行交易算法的早期采用者。他們很早就意識到人工智能在金融領(lǐng)域以外的潛力,以及規(guī)模化的關(guān)鍵見解。
因此,他們一直在持續(xù)增加GPU的供應(yīng)。在嘗試使用數(shù)千個(gè)GPU的集群模型后,High-Flyer(幻方)在2021年做出了投資,購買了10000個(gè)A100 GPU,當(dāng)時(shí)還沒有任何出口限制。這得到了回報(bào)。
隨著High-Flyer(幻方)的改進(jìn),他們意識到是時(shí)候在2023年5月剝離出“DeepSeek”了,目標(biāo)是追求更專注、更進(jìn)一步的AI能力。High-Flyer(幻方)自籌資金,因?yàn)楫?dāng)時(shí)外部投資者對AI幾乎沒有興趣,缺乏商業(yè)模式是主要擔(dān)憂。High-Flyer(幻方)和DeepSeek今天經(jīng)常共享資源,包括人力和計(jì)算資源。
DeepSeek現(xiàn)在已經(jīng)發(fā)展成為一個(gè)嚴(yán)肅的項(xiàng)目,絕不像許多媒體所說的那樣是一個(gè)“副業(yè)項(xiàng)目”。我們有信心,即使考慮到出口管制,他們的GPU投資也超過5億美元。
三、GPU的情況
我們相信他們可以訪問大約50000個(gè)英偉達(dá)Hopper GPU ,這與一些人聲稱的50000個(gè)H100不同。英偉達(dá)根據(jù)不同的法規(guī)制造了不同版本的H100(H800、H20),目前只有H20可以供中國型號提供商使用。注意,H800的計(jì)算能力與H100相同,但網(wǎng)絡(luò)帶寬更低。
我們相信DeepSeek有大約10000個(gè)H800和大約10000個(gè) H100。此外,他們還有更多的H20訂單,英偉達(dá)在過去9個(gè)月中生產(chǎn)了超過100萬個(gè)中國專用GPU。這些GPU在High-Flyer(幻方)和DeepSeek之間共享,并在一定程度上地理分布。它們用于交易、推理、培訓(xùn)和研究。

我們的分析顯示,DeepSeek的總服務(wù)器資本支出幾乎達(dá)到13億美元,其中相當(dāng)大一部分成本(7.15億美元)與運(yùn)營此類集群有關(guān)。
DeepSeek只從中國招募人才,不考慮之前的資歷,非常注重能力和好奇心。DeepSeek經(jīng)常在頂尖大學(xué)如北京大學(xué)和浙江舉辦招聘活動,許多員工畢業(yè)于這些大學(xué)。職位不一定是預(yù)先定義的,招聘過程是他們的招聘廣告甚至宣稱可以擁有10,000個(gè)GPU,且沒有使用限制。他們非常具有競爭力,據(jù)稱會為有前途的候選人提供超過130萬美元的薪水,遠(yuǎn)遠(yuǎn)超過中國的大型科技公司。他們擁有約150名員工,但正在迅速增長。
正如歷史所顯示的那樣,一家資金充足且專注的初創(chuàng)公司往往能夠突破可能性的界限。DeepSeek缺乏像谷歌這樣的官僚機(jī)構(gòu),并且由于他們自籌資金,可以在想法上快速行動。
然而,與谷歌一樣,DeepSeek(在很大程度上)運(yùn)行自己的數(shù)據(jù)中心,而不依賴外部方或提供商。這為實(shí)驗(yàn)開辟了更多空間,使他們能夠在整個(gè)堆棧上進(jìn)行創(chuàng)新。
我們相信他們是當(dāng)今最好的“開源權(quán)重”實(shí)驗(yàn)室,擊敗了Meta的Llama、Mistral和其他實(shí)驗(yàn)室。
四、DeepSeek的成本和性能
DeepSeek的價(jià)格和效率本周引發(fā)了狂熱,頭條新聞是DeepSeek V3的訓(xùn)練成本為“600萬美元”。這是錯誤的。這類似于指向產(chǎn)品材料清單的某個(gè)特定部分并將其歸為整個(gè)成本。預(yù)訓(xùn)練的成本在總成本中占非常小的一部分。
1.訓(xùn)練費(fèi)用
我們相信預(yù)訓(xùn)練的數(shù)字遠(yuǎn)遠(yuǎn)低于實(shí)際在模型上花費(fèi)的金額。我們確信他們的硬件支出遠(yuǎn)高于5億美元。為了開發(fā)新的架構(gòu)創(chuàng)新,在模型開發(fā)期間,有相當(dāng)大的支出用于測試新想法、新架構(gòu)思想和改進(jìn)。
DeepSeek的一項(xiàng)關(guān)鍵創(chuàng)新——多頭潛在注意力——花費(fèi)了大量資金。花了幾個(gè)月才開發(fā)出來,并花費(fèi)整個(gè)團(tuán)隊(duì)的人力和GPU時(shí)間。
論文中提到的600萬美元成本僅包括預(yù)訓(xùn)練運(yùn)行中的GPU成本,而這只是模型總成本的一部分。研發(fā)以及硬件本身的總擁有成本等重要部分被排除在外。作為參考,Claude 3.5 Sonnet需要花費(fèi)數(shù)百萬美元進(jìn)行訓(xùn)練,如果這是Anthropic所需的總成本,那么他們就不會從谷歌籌集數(shù)十億美元,從亞馬遜籌集數(shù)百億美元。這是因?yàn)樗麄儽仨氝M(jìn)行實(shí)驗(yàn),提出新的架構(gòu),收集和清理數(shù)據(jù),支付員工費(fèi)用等等。
那么, DeepSeek 是如何擁有如此龐大的集群的呢?出口控制的滯后是關(guān)鍵所在,將在下面的出口部分進(jìn)行討論。
2.縮小差距——V3的性能
V3無疑是一個(gè)令人印象深刻的模型,但值得強(qiáng)調(diào)的是相對于什么而言令人印象深刻。許多人將V3與GPT-4o進(jìn)行了比較,并強(qiáng)調(diào)了V3如何擊敗了4o的性能。這是真的,但GPT-4O是在2024年5月發(fā)布的。AI 進(jìn)展迅速,2024 年 5 月是算法改進(jìn)的另一個(gè)生命周期。
此外,我們并不驚訝地發(fā)現(xiàn),在給定的時(shí)間后,需要更少的計(jì)算就能實(shí)現(xiàn)類似或更強(qiáng)的能力。推理成本下降是 AI 改進(jìn)的標(biāo)志。
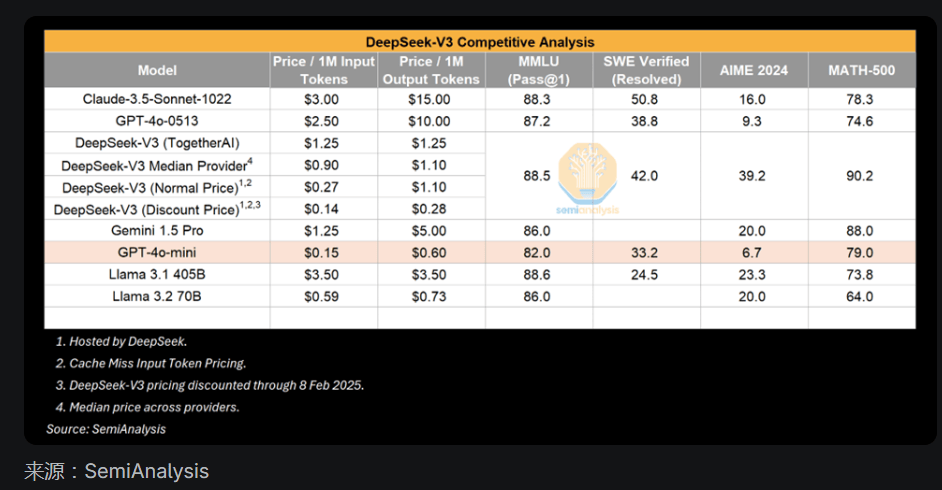
一個(gè)例子是,可以在筆記本電腦上運(yùn)行的小模型具有與GPT-3相當(dāng)?shù)男阅埽珿PT-3需要一臺超級計(jì)算機(jī)來訓(xùn)練和多個(gè)GPU來推斷。
換句話說,算法的改進(jìn)允許更少的計(jì)算量來訓(xùn)練和推斷相同能力的模型,這種模式反復(fù)出現(xiàn)。這次世界注意到了這一點(diǎn),因?yàn)樗鼇碜灾袊膶?shí)驗(yàn)室。但小型模型越來越好并不是新鮮事。
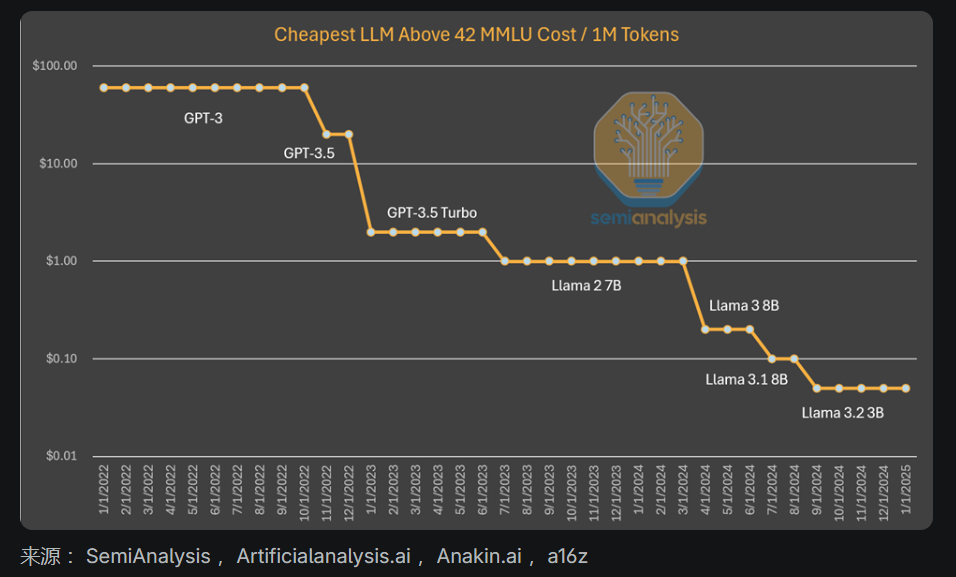
到目前為止,我們所見證的模式是,人工智能實(shí)驗(yàn)室花費(fèi)了更多的絕對資金,以獲得更智能的產(chǎn)品。據(jù)估計(jì),算法進(jìn)展為每年4次,這意味著每過一年,實(shí)現(xiàn)相同能力所需的計(jì)算量會減少4倍。Anthropic(OpenAI的死對頭)的執(zhí)行官達(dá)里奧認(rèn)為, 算法的進(jìn)步甚至更快,并且可以產(chǎn)生一個(gè)10倍的改進(jìn)。就GPT-3質(zhì)量的推理定價(jià)而言,成本已經(jīng)下降了1200倍。
當(dāng)研究GPT-4的成本時(shí),我們看到類似的成本下降,盡管是在曲線的早期。雖然成本差異的減少可以解釋為不再那樣保持能力恒定。在這種情況下,我們看到算法的改進(jìn)和優(yōu)化創(chuàng)造了成本下降了10倍,而能力增加。
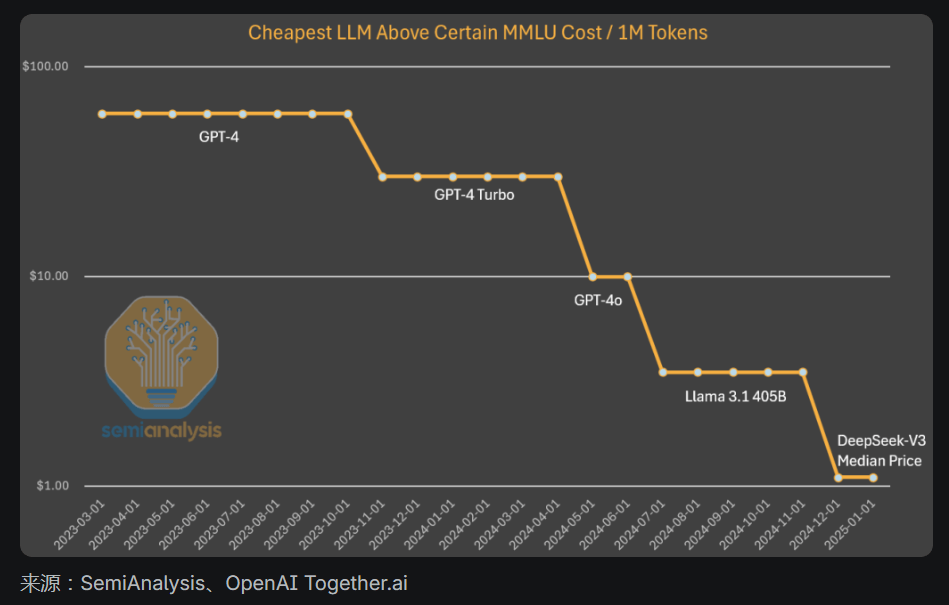
需要明確的是,DeepSeek的獨(dú)特之處在于他們首先實(shí)現(xiàn)了這種成本和能力。他們在發(fā)布開放重量方面是獨(dú)一無二的,但之前的Mistral和Llama模型也曾這樣做過。DeepSeek已經(jīng)實(shí)現(xiàn)了這種成本水平,但如果到年底,成本再下降5倍,也不要感到震驚。
3.R1的性能與o1匹配嗎?
另一方面,DeepSeek R1能夠取得與GPT o1相當(dāng)?shù)某煽儯鴒1在9月份才剛剛公布,DeepSeek怎么能這么快趕上來呢?
答案是,推理是一種新的范式,具有更快的迭代速度,比以前的范式在更小的計(jì)算量下獲得了有意義的收益。正如我們在本文中概述的那樣,以前的模式依賴于預(yù)訓(xùn)練,而這變得越來越昂貴,也越來越難以取得穩(wěn)健的成果。
新范式專注于通過合成數(shù)據(jù)生成和強(qiáng)化學(xué)習(xí)后在現(xiàn)有模型上進(jìn)行后期訓(xùn)練來提高推理能力,從而以更低的價(jià)格更快地獲得收益。
較低的進(jìn)入門檻加上易于優(yōu)化意味著DeepSeek能夠比平時(shí)更快地復(fù)制o1方法。隨著玩家在新范式中找到更多的擴(kuò)展方式,我們預(yù)計(jì)匹配能力之間的時(shí)間差距將會增加。
請注意,R1論文沒有提到所使用的計(jì)算量。這不是偶然的——為訓(xùn)練后的R1生成合成數(shù)據(jù)需要大量的計(jì)算量。更不用說RL了。
R1是一個(gè)非常好的模型,我們對此沒有異議,而且如此迅速地趕上推理優(yōu)勢,在客觀上令人印象深刻。DeepSeek是中國的,并且資源更少,這一事實(shí)讓它更加令人印象深刻。
但R1提到的一些基準(zhǔn)也是誤導(dǎo)。比較R1和o1是很棘手的,因?yàn)镽1并未明確提及它們不領(lǐng)先的基準(zhǔn)。雖然R1在推理性能上與之匹配,但在每個(gè)指標(biāo)上都不是明顯的贏家,在許多情況下它比o1更差。
我們還沒有提到o3。o3的能力顯著高于R1或o1。事實(shí)上,OpenAI最近分享了o3的結(jié)果,基準(zhǔn)擴(kuò)展是垂直的。“深度學(xué)習(xí)遇到了瓶頸”,但類型不同。

4.谷歌的推理模型和R1一樣好
雖然DeepSeek R1被瘋狂炒作,但一個(gè)月前,一家市值2.5萬億美元的美國公司發(fā)布了一款更便宜的推理模型:谷歌的Gemini Flash 2.0 Thinking。這款模型可以使用,并且比R1便宜得多。即使通過API為模型提供了更大的上下文長度。
在已報(bào)道的基準(zhǔn)測試中,谷歌的Flash 2.0 Thinking擊敗了DeepSeek R1,盡管基準(zhǔn)測試并不能說明全部情況。谷歌只發(fā)布了3個(gè)基準(zhǔn)測試,所以這還不完整。
盡管如此,我們認(rèn)為谷歌的模式是穩(wěn)健的,在許多方面與DeepSeek R1抗衡,但沒有受到任何炒作。這可能是因?yàn)楣雀璧臓I銷策略乏善可陳和用戶體驗(yàn)差,但R1是一個(gè)中國人的驚喜。
需要明確的是,這些都不會影響DeepSeek的顯著成就。DeepSeek作為一家快速發(fā)展、資金充足、聰明且專注的初創(chuàng)公司的結(jié)構(gòu),正是它擊敗Meta等巨頭的原因。在發(fā)布推理模型時(shí),這是值得稱贊的。
五、技術(shù)成就
DeepSeek破解了代碼并解鎖了領(lǐng)先實(shí)驗(yàn)室尚未實(shí)現(xiàn)的創(chuàng)新。我們預(yù)計(jì)DeepSeek發(fā)布的任何改進(jìn)幾乎會立即被西方實(shí)驗(yàn)室效仿。
這些改進(jìn)是什么?大多數(shù)架構(gòu)成就都與DeepSeek V3相關(guān),這也是R1的基礎(chǔ)模型。讓我們詳細(xì)介紹這些創(chuàng)新。
1.訓(xùn)練(前期和后期)
DeepSeek V3在以前從未見過的規(guī)模上使用了多標(biāo)記預(yù)測(MTP),這些是附加的注意力模塊,用于預(yù)測接下來的幾個(gè)標(biāo)記,而不是單個(gè)標(biāo)記。這在訓(xùn)練期間提高了模型性能,并在推理期間可以丟棄。這是一個(gè)算法創(chuàng)新的例子,使性能在更低的計(jì)算量下得到改善。
還有一些額外的考慮因素,比如在訓(xùn)練中提高FP8(8位浮點(diǎn)格式)的準(zhǔn)確性,但美國領(lǐng)先的實(shí)驗(yàn)室已經(jīng)進(jìn)行了一段時(shí)間的FP8訓(xùn)練。
DeepSeek v3 也是專家模型的混合體,這是一個(gè)由許多其他小型專家組成的大模型,這些專家專門從事不同的事情。MoE(專家混合)模型面臨的一個(gè)難題是如何確定哪個(gè)標(biāo)記會到達(dá)哪個(gè)子模型或“專家”。DeepSeek 實(shí)現(xiàn)了一個(gè)“路由網(wǎng)絡(luò)”,以一種平衡的方式將標(biāo)記路由到正確的專家,而不影響模型性能。
這意味著路由非常高效,在訓(xùn)練每個(gè)標(biāo)記時(shí),相對于模型的整體規(guī)模,只會改變一些參數(shù)。這增加了訓(xùn)練效率和推理成本。
盡管有人擔(dān)心專家混合(MoE)效率的提高可能會減少投資,但達(dá)里奧表明,更強(qiáng)大的人工智能模型的經(jīng)濟(jì)效益是如此巨大,以至于任何成本節(jié)約都會迅速重新投資于構(gòu)建更大的模型。
MoE(專家混合)的效率提高不會減少整體投資,而是將加速AI的擴(kuò)展努力。這些公司專注于將模型擴(kuò)展到更多的計(jì)算資源,并在算法上提高它們的效率。
在DeepSeek R1方面,它從擁有一個(gè)穩(wěn)健的基礎(chǔ)模型(v3)中受益匪淺。這部分歸功于強(qiáng)化學(xué)習(xí)(RL)。RL有兩個(gè)重點(diǎn):格式化(以確保它提供連貫的輸出)以及有用性和無害性(以確保模型有用)。推理能力在對合成數(shù)據(jù)集進(jìn)行微調(diào)時(shí)顯現(xiàn)出來。這就是O1所發(fā)生的事情。
請注意,在R1論文中沒有提到計(jì)算量,這是因?yàn)樘岬绞褂昧硕嗌儆?jì)算量會表明他們擁有的GPU比他們的敘述所暗示的要多。如此規(guī)模的RL(強(qiáng)化學(xué)習(xí))需要大量的計(jì)算量,特別是生成合成數(shù)據(jù)。
此外,DeepSeek使用的一部分?jǐn)?shù)據(jù)似乎來自O(shè)penAI的模型,我們認(rèn)為這將對從輸出數(shù)據(jù)提取政策產(chǎn)生影響。這在服務(wù)條款中已經(jīng)是非法的,但未來的新趨勢可能是采用某種形式的KYC(了解你的客戶)來阻止提取。
說到蒸餾, DeepSeek R1論文中最有趣的部分可能是能夠通過微調(diào)推理模型的輸出,將非推理的小型模型轉(zhuǎn)化為推理模型。數(shù)據(jù)集整理包含總共80萬個(gè)樣本,現(xiàn)在任何人都可以使用R1的CoT輸出創(chuàng)建自己的數(shù)據(jù)集,并在這些輸出的幫助下創(chuàng)建推理模型。我們可能會看到更多的小型模型展示推理能力,從而提高小型模型的性能。
2.多頭潛在注意(MLA)
MLA是一項(xiàng)關(guān)鍵的創(chuàng)新,顯著降低了DeepSeek的推理價(jià)格。原因是MLA將每個(gè)查詢所需的KV緩存量(指在大模型推理過程中,鍵值緩存KV Cache所占用的內(nèi)存大小)減少了約93.3%。
與標(biāo)準(zhǔn)注意力相比,KV緩存是變換器模型中的一種內(nèi)存機(jī)制,用于存儲表示對話上下文的數(shù)據(jù),從而減少不必要的計(jì)算。
正如在我們的縮放法則文章中所討論的,KV緩存會隨著對話上下文的增長而增長,并產(chǎn)生相當(dāng)大的內(nèi)存約束。大幅減少每個(gè)查詢所需的KV緩存量,會減少每個(gè)查詢所需要的硬件量,從而降低成本。
然而,我們認(rèn)為DeepSeek是在以成本為代價(jià)提供推理以獲取市場份額,而實(shí)際上并沒有賺到任何錢。谷歌Gemini Flash 2 Thinking仍然更便宜,谷歌不太可能以成本價(jià)提供這種產(chǎn)品。MLA特別吸引了許多美國領(lǐng)先實(shí)驗(yàn)室的目光。MLA在DeepSeek V2中發(fā)布,該版本于2024年5月發(fā)布。
第一步:提交您的答案
第二步:待廣告主審核通過
第三步:獲得任務(wù)活躍值
同類任務(wù)

暫無同類任務(wù)
